
Kubernetes笔记
写在开头
为什么叫K8S? 因为K到S之间有8个字母。
为什么需要K8S?
参考
【阿里云技术公开课】https://edu.aliyun.com/roadmap/cloudnative
【K8S官方中文文档】http://docs.kubernetes.org.cn/
【kuboard:免费K8S教程(图文)】https://kuboard.cn/learning/
K8S的作用
- 服务发现和负载均衡
- 存储编排
- 自动部署和回滚
- 自动完成装箱(为容器选择物理主机,并将容器部署上去)
- 自我修复(容器所在主机出现故障,自动将容器迁移到别的主机上)
- 密钥与配置管理
- 批量执行
- 水平伸缩(发现容器所在主机负载过高,自动在别的主机部署多个容器副本,提高负载)
K8S的架构
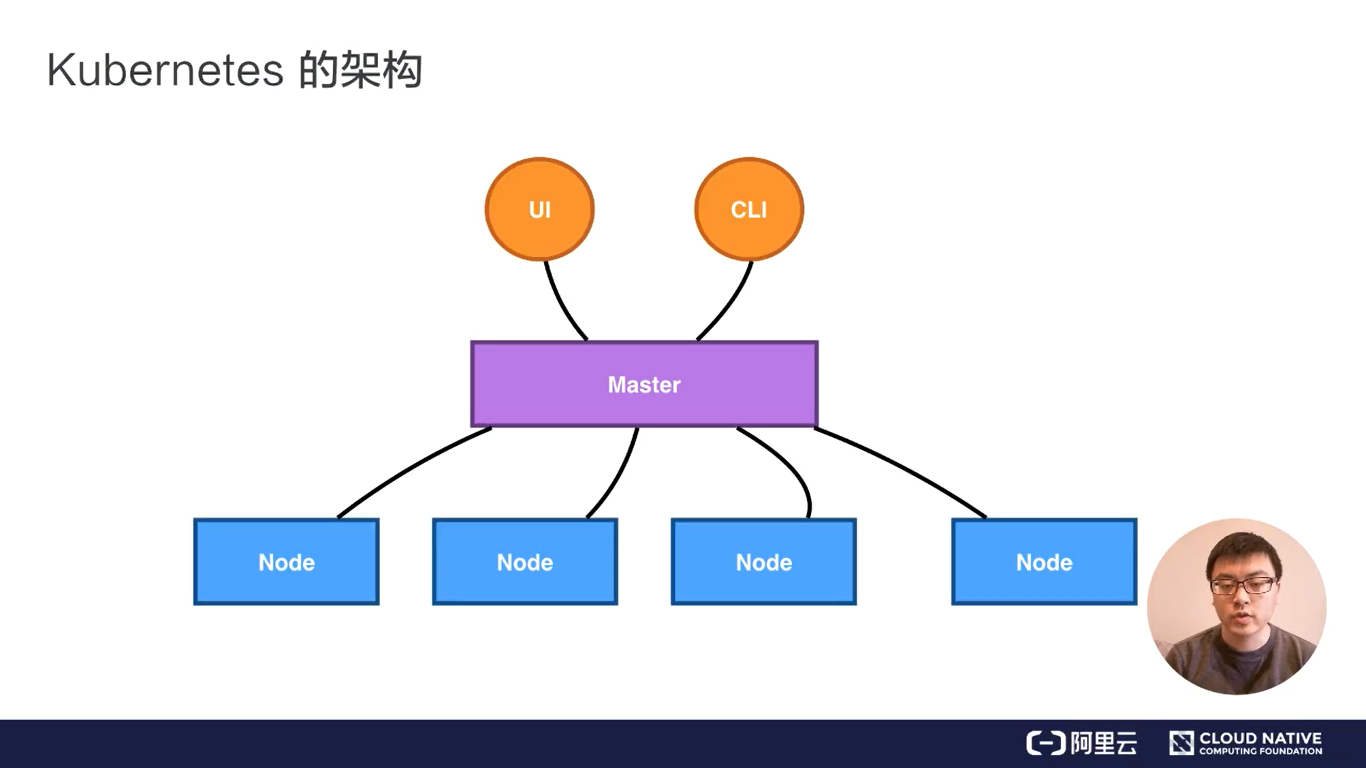
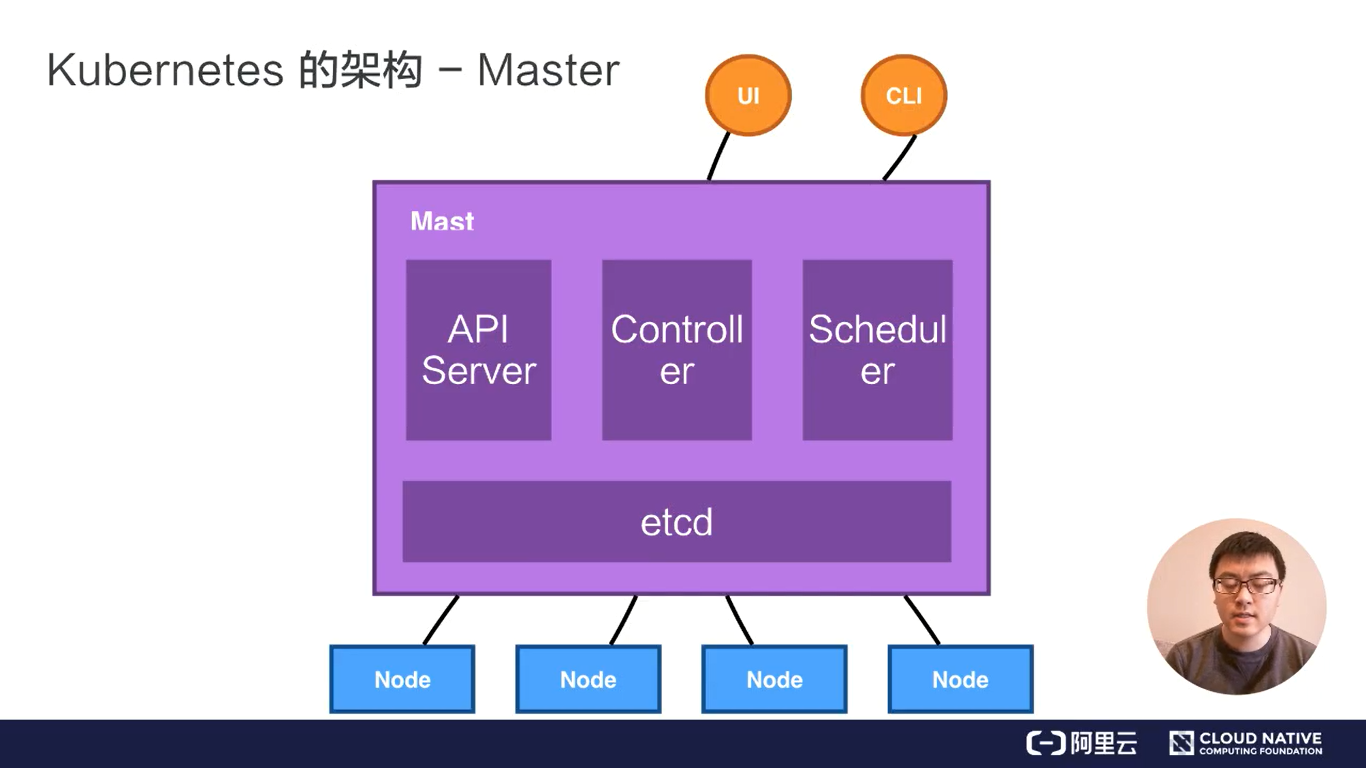
Master节点
有四大组件:
- API Server(组件之间均通过API Server进行通信)
- Controller(负责容器状态管理。例如自我修复、水平伸缩等)
- Schedular(调度器,负责容器的部署、装箱)
- etcd(键值对数据库,分布式存储系统,保存API Server的元数据)
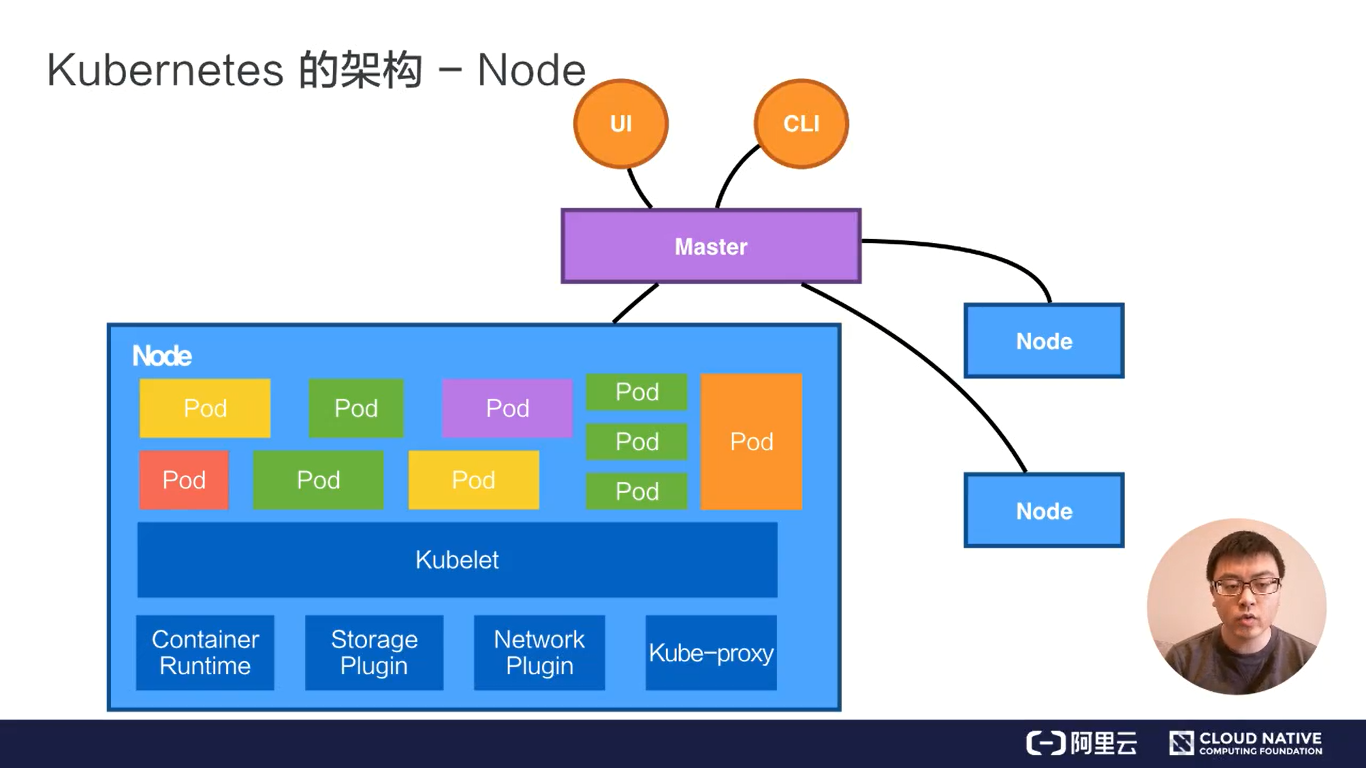
Node节点
有以下组件:
- pod(容器集)
- Kubelet(容器生命周期管理、节点信息同步、接收并处理来自Master的请求)
- Container-runtime(容器运行时、容器引擎)
- docker(1.20版本后开始弃用,原因:docker不支持CRI接口)
- containerd
- CRI-O
- Storage plugin
- Network Plugin(kube-proxy)
pod 和 docker是什么关系?
docker是容器,负责装载我们应用程序的不同部分(mysql、前端、后端、redis等) pod则是容器集,包含多个容器,并由这些容器组成一个完整的应用;pod中的容器共享一些资源(数据卷、进程号、端口、域名主机名等) 参考:Linux namespace 资源隔离 沙箱技术
Kube-proxy(管理pod之间的通信)
负责与本地Iptables打交道。
什么是 Iptables?什么是IPVS?
Linux防火墙的组件
在Linux系统中,由一个叫netfilter的框架提供真正的防火墙安全框架,运行在内核态;
而Iptables、IPVS则是netfilter的代理,运行在用户态;
用户通过操作Iptables、IPVS这些命令行工具,去操作真正的防火墙框架。
防火墙有什么功能?
- 过滤报文
- 网络地址转换(NAT)
- 拆解报文,重新封装
kube-proxy与userspace、iptables、ipvs是什么关系?
kube-proxy通过底层调用这些工具,去实现防火墙运维的功能。
其他插件
CoreDNS(域名管理)
维护Service的IP与域名之间的映射关系
Dashboard(控制台)
可视化K8S控制台
Ingress(负载均衡)
有了kube-proxy的存在,为什么还需要Ingress?
Ingress可实现七层负载均衡
Federation(K8S集群管理系统)
Prometheus(K8S监控平台)
ELK(K8S日志分析平台)
Harbor(私有容器仓库)
K8S工作流程的原理
部署一个容器组(POD)
- 用户提交一个POD(容器)到API Server;
- API Server将POD信息保存到etcd;
- API Server通知Schedular,为POD分配物理主机进行部署;
- Schedular接收到请求,为POD选择装箱的节点,生成部署任务;
- API Server收到部署任务,将部署任务先保存到etcd;
- 再将部署任务分发到相应的Node节点中;
- Node中的Kubelet负责接收请求,并调用各种Plugin(Storage Plugin、Network Plugin、Kube-proxy组建网络、申请空间)
- 最后容器运行在Node的Container-Runtime中;
K8S的基础概念
资源清单(yaml)
K8S的所有内容都被抽象化为资源。 资源实例化后,叫做对象。 资源通过资源清单来描述以及创建。
资源按如下分类:
命名空间级别
- 工作负载型资源:Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、CronJob
- 服务发现及负载均衡型资源:Ingress、Service...
- 配置与存储型资源:Volume(存储卷)、CSI(容器存储接口,可链接到第三方存储卷)
- 特殊类型的存储卷:ConfigMap(配置中心)、Secret(敏感数据)、DownwardAPI(将外部环境的信息输出给容器)
集群级别 Namespace(命名空间)、Node(工作节点)、Role、ClusterRole、RoleBinding、ClusterRoleBinding
元数据级别 HPA、PodTemplate、LimitRange(资源限制)
资源清单是用于资源创建的一个描述文件。
Pod资源清单示例:
#pod.yaml
apiVersion: v1
kind: Pod #资源类型(首字母必须大写)
metadata: #pod的基础信息
name: myapp-pod
namespace: default
labels:
app: myapp
version: 1.0
spec: #详细的描述信息
containers: #包含哪些容器
- name: mysql #容器1:mysql
image: mysql:latest
command: ['sh','-c','echo the app is running!'] #启动后执行的脚本
- name: readingness-httpget-container #容器2
image: myapp:v1
imagePullPolicy: IfNotPresent #镜像拉取策略:IfNotPresent为若本地没有则拉取
readinessProbe: #定义一个就绪探针
httpGet:
port: 80
path: /index.html
periodSeconds: 3 #每3s检测一次
livenessProbe: #定义了一个存活探针
exec: #exec:通过执行某段脚本的返回值判断。还有httpGet、tcp(详见“探针”)
command: ["test","-e","/tmp/live"]
lifeCycle:
preStart: #容器启动前,执行的脚本(配置方法类似于探针)
exec:
command: ...
preStop: #容器停止前,执行的脚本(配置方法类似于探针)
exec:
command: ...
initContainers: #包含哪些Init容器
- name: mysql-init
image: mysql:latest
command: ['sh','-c','until nslookup mydb;do echo waiting for mydb;sleep 2; done;']
可通过以下命令查看资源清单有哪些属性
#查看pod资源清单有哪些属性
kubectl explain pod
#查看pod资源清单的metadata有哪些属性
kubectl explain pod.metadata
写好Pod的资源清单后,执行以下命令:
#按照资源清单部署资源
kubectl apply -f pod.yaml
#查看当前pod资源列表
kubectl get pod
Namespace(命名空间)
将Pod(容器集)、Deployment(容器集集群)、Service(网关)、Volume(存储卷)等资源进行逻辑分组,规划到一个小组内进行管理,这个小组便被称为一个Namespace; 同一个命名空间内的这些资源不允许重名,不同命名空间的可以重名;
用户资源所属默认的命名空间:default
系统资源所属的命名空间:kube-system
Pod(容器集)
在集群中创建和部署的最小单元。一个pod部署在一台物理主机上。
一个Pod包含一个到多个容器。
支持多种容器环境(Docker、containerd、CRI-O)。
Pod内容器的端口不能冲突。
Pod的属性
标签(Label) 格式:key:value
可以用标签对Pod进行标识;如标识某个Pod为前端应用、标识某个Pod为生产环境等。
查找Pod时可通过标签进行查找。用类似于SQL的方式(例如:ENV=prod)
注解(annotations) 格式:key:value
类似于备注。可存储特殊字符。
所有者(OwnerReference) Pod上面还可以组成一个Pod的集合。OwnerReference就是描述Pod与Pod集合之间的关系。
Pod集合包括:replicaset、statefulset
特殊的容器:Infra容器(又叫“pause容器”)
Infra容器是每个pod启动的第一个容器,负责准备pod需要的网络与数据卷;
Infra容器由系统自动维护,无需用户定义;
pod内:容器共享Infra容器的网络栈和挂载卷(使容器之间可通过localhost访问);
pod外:容器通过Infra容器与其他pod的容器交互;
Infra容器存在于pod的整个生命周期中;
特殊的容器:Init容器
Init容器用于Pod中环境的准备,而且是一些不被建议放到应用程序容器镜像中的准备工作。
Init容器由用户自定义;
Init容器可以有0~n个;
Init容器只存在于Pod的初始化阶段;当Init容器完成任务后便会自行结束;
Pod中容器共享的资源有:
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
UTS命名空间:Pod中的多个容器共享一个主机名;
Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volumes;
Deployment(集群)
ReplicaSet提供了命令式编程的方式来创建Pod(create);
而Deployment则提供了声明式编程的方式来创建Pod(apply)。
Deployment的作用:
- 可确保Deployment中正常运行的Pod数量(当有Pod挂掉后,可自动重新发布一个Pod)
- Pod版本更新若出现问题,支持一键回滚
- 可配置Pod版本更新的策略
- 支持滚动更新(rolling-update)
Deployment的用例: 将Pod分类,将不同类型的Pod分到不同的Deployment中,方便管理。
例如:
Pod A:前端(3个)
Pod B:后端(3个)
Pod C:数据库(1个)
Pod D:网关(1个)
可将3个前端的Pod(即Pod A)分到一个Deployment中。
Deployment的工作原理: 当kubelet接到API Server的请求,需要滚动更新:
- 为Deployment创建一个新RS(Replicaset,见“控制器”),由RS负责创建并管理新的Pod;
- 调用Deployment的旧RS,旧RS每删除一个旧的Pod,新RS便创建一个新的Pod,达到滚动更新;
- 当新pod数量达到期望值,停止创建。
Service(网关、服务发现、负载均衡)
Service与Deployment一样,为一组Pod服务;
Deployment为Pod集群提供了版本更新的支持,Service则是作为Pod集群的代理,提供了服务注册、负载均衡的支持;
Service对应着一个IP+端口地址。
需要解决什么问题:
服务注册的原理?
如何进行负载均衡?
解决了什么问题:
Service等于在Nginx层和APP层的中间的一层;负责将APP Pod的服务动态注册到Nginx上;
Service的实现类型:
ClusterIP
分配一个仅集群内部可以访问的IP:Port地址(ClusterIP),集群中的其他Pod便可通过ClusterIP访问Service,进而访问Service匹配的Pod集群;
Service会将请求通过iptables转发给kube-proxy,由kube-proxy负载均衡,将请求发送至合适的Pod。
Headless Service(无头服务)
也是ClusterIP Service的一种,它不向外部提供IP地址(ClusterIP=null)
访问Headless Service需要通过CoreDNS中无头服务对应的主机名去访问。#查看CoreDNS信息 kubectl get pod -n kube-system -o wide
NodePort
在ClusterIP的基础上,将Service绑定到主机的某个端口中,外部机器就可以通过该端口访问到Service匹配的Pod集群;
LodBalance
在NodePort的基础外加了一层云负载均衡(LAAS,需要租金);
即外部主机通过云负载均衡提供商去访问不同主机的NodePort,NodePort再转发请求给对应的Pod集群。
ExternalName
把集群外部的服务注册到集群内部来,通过一个服务名进行访问。
存储(etcd、configMap、secret、volume、PV)
存储类型有:
- ConfigMap(配置文件注册中心,键值对存储)
- Secret
- Volume
- Persistence Volume(PV)
ConfigMap K8S统一保存所有Pod的key-value键值对。
如何通过资源清单定义ConfigMap;
如何在Pod资源清单的环境变量中调用ConfigMap;
如何在Pod资源清单的命令中调用ConfigMap;
如何在Pod资源清单中调用ConfigMap作为配置文件;
Secret
K8S统一保存所有Pod的密码、token、密钥等敏感信息。
有三种类型:
- Service Account
- Opaque
- kubernetes.io/dockerconfigjson
Volume
Pod中的容器可共享的一个存储空间。容器之间可通过Volume(卷)共享文件。
K8S支持Volume的很多实现框架:
azureFile、cephfs、emptyDir、hostPath、nfs、gitRepo、glusterfs等等。
控制器(Controller)
下面是不同控制器的介绍。
replicaset(RS):负责创建pod、删除pod,维持pod副本在期望数目
replication controller(RC):功能与RS类似,但RS在RC基础上还支持集合式的selector(被推荐用replicaset取代)
statefulSet(有状态服务集):解决有状态服务的问题。
什么是有状态服务? 就是服务器提供的服务,会保留用户请求的信息,就算有状态服务。 例如需要维护session的应用、持久化存储(数据库)等。 一般不推荐有状态服务部署到K8S。
statefulSet的应用场景:
- 持久化存储:pod重新调度后,依然能访问到相同的持久化数据,基于PVC
- 稳定的网络标志:pod重新调度后,PodName和Hostname保持不变,基于Headless Service
- 有序部署:将pod按照一定顺序部署(如先部署mysql、再部署app、再部署nginx),基于Init容器实现。
- 有序收缩:有序移除pod(先移除nginx,再app、mysql)
DaemonSet(守护进程集):在符合条件的节点上均部署某一类的pod。
常用于以下场景:
- 日志收集:如在每个节点均需要部署一个LogStash、Fluentd的容器
- 系统监控:Prometheus Node Exporter、Zabbix
- 集群存储:Glusterd、Ceph
与JAVA中AOP(面向切面)的思想类似。
将日志收集、系统监控等的、基本上每个Node都需要用到的服务提取出来,作为一个切面;
该切面有一个selector表达式,符合表达式的Node在加入集群时,DaemonSet会为它们新增一个Pod;反之,当这些Node退出集群时,这些Pod会被回收。
Job、CronJob:负责批处理任务,即只执行一次的任务。
常用于需要执行一些脚本的时候。
Job会创建一个或多个Pod去执行任务。
CronJob与Job类似,只不过CronJob可以周期性执行任务,Job是只执行一次。
horizontal pod autoscaling(HPA) :通过监控资源使用情况(CPU、内存),提示控制器去控制pod的数量
网络
Pod内容器之间的通信:lo(本机回环接口,pause容器的网络栈)
Pod与Pod之间的通信:Overlay Network
Pod与Service之间的通信:各节点的IPTables规则
Flannel
可以使不同主机上创建的容器都具有全集群唯一的虚拟IP地址。
调度器(Schedular)
探针(Handler)
探针是由kubelet对容器进行的定期检测。
探针类型:
- ExecAction:在容器内执行指定命令,返回0则认为诊断成功。
- TCPSocketAction:对指定端口的容器的IP地址进行TCP检查。端口打开的则认为诊断成功。
- HTTPGetAction:对指定端口的容器的IP地址发送HTTP Get请求,返回状态码为200以上400以下则认为诊断成功。
探针有两种用途:
livenessProbe:存活探针。若这种类型的探针诊断失败,则K8S认为容器没有在运行,会将容器杀死,并且容器将受到重启策略 的影响。
readingProbe:就绪探针。若这种类型的探针诊断失败,则K8S认为该容器未准备好服务Service,并从Service的端点中删除该Pod的IP地址。
安全控制
HELM(类似于Linux中的yum,包管理工具)
集群安装:例如通过helm安装mongodb集群、mysql集群
Kubernetes 组件
- kubectl:客户端命令行工具
- kube-apiserver:服务端进程,以 REST API 服务提供接口。
- kube-controller-manager:用来执行整个系统中的后台任务,包括节点状态状况、Pod 个数、Pods 和 Service 的关联等。
- kube-scheduler(将 Pod 调度到 Node 上):负责节点资源管理,接受来自 kube-apiserver 创建 Pods 任务,并分配到某个节点。
- kubelet:运行在每个计算节点上,作为 agent,接受分配该节点的 Pods 任务及管理容器,周期性获取容器状态,反馈给 kube-apiserver。
- DNS:一个可选的DNS服务,用于为每个 Service 对象创建 DNS 记录,这样所有的 Pod 就可以通过 DNS 访问服务了。
编排管理层的组件:
- etcd:节点间的服务发现和配置共享。
- kube-proxy:负责 Pod 网络代理。
- flannel:云端网络配置,需要另外下载部署。